

概述
随着 AI孙燕姿 的爆红以及想要将 AI 融入到自己的工作流中,提升工作效率的冲动再次袭来;我打算利用 AI 克隆出自己的声音,用于后续的视频剪辑中,免去届时后期配音的工作流程。
因此,在经过一系列的权衡之后,决定使用 so-vits-svc(本文后续简称 svs)。但在实际搜寻教程的过程中,发现很多都忽略了其中的很多步骤,处于职业习惯,实在忍无可忍,也就有了这篇笔记。
这篇笔记将事无巨细地将从svc的部署到最后使用模型替换声音整个流程讲清楚。也就是说本文将涵盖以下内容:
- 最终成果展示;
- 我是否符合使用条件;
- svc部署;
- 声音数据集准备;
- 声音数据的采集;
- 声音数据的清洗;
- 模型训练;
- 模型使用 (产出);
- 注意事项;
请务必按照本文目录顺序阅读/操作,以节省时间。
最终成果
音频效果是使用模型产出的音频 Que sera sera 及 开始懂了, 使用 肥振华 的声音替换 手嶌葵 及 孙燕姿 的原唱。
也可以思考一下这样的选择是否存在问题,为什么
Que sera sera-AI肥振华 (1556轮训练,原音频:手嶌葵)
开始懂了-AI肥振华 (500轮训练,原音频:孙燕姿)
朗读文字部分的使用场景由于隐私原因就不展示了。
在部署前
碎碎念
SVC 这个项目的初心是一群二次元程序员(媛)们为了让自己喜欢的动漫角色能够唱一些自己喜欢的歌。完全没有克隆真人声音的想法。但正如项目中所说的:The project was developed to allow the developers' favorite anime characters to sing, Anything involving real people is a departure from the intent of the developer. 事情发展到现在,用于对真人声音复制,完全出乎了开发者的预料。
SVC 可以用较少的人声样本进行训练,学习一个人的声音之后,替换一段音频中的人说话的音色。如:音频A 中的话原本是 川建国 讲的, 可以通过采集 马保国 的声音素材进行训练后,将视频A中川建国说话的声音替换成马保国。
直接部署的话,门槛还是比较高的,而且在部署期间一定会遇到某些依赖安装不成功的情况。虽说这些问题可以通过搜索的方式找到解决办法(泪目),但极其耗时。而且,更加令人崩溃的是,在手动部署完成之后,在 B站搜索,发现有已经有博主把自己安装好的环境整理成了整合包。用那个整合包可以跳过浪费生命的依赖安装过程。 因不想写依赖安装的失败的处理方法,本文将采用整合包方案。
本文涉及的所有代码、模型 (网易 ncm 格式解密代码以外),均可在本文末尾找到并下载
我是否符合使用条件
如需使用 svc,你需要具备以下条件:
- windows 系统 ( macos 安装会容易很多,但因为 macos 不支持 cuda ,因此个人不建议;而使用 linux 的同学不会看到我这篇文章;因此在此仅建议使用 windows);
- 安装 6G 显存以上的显卡,并且已安装正确版本的cuda;
- 安装运行环境 python 3.8.9 (可选);
SVC部署
本章节假定读者下载的是 本文的整合包 ,下载完成并解压到 D 后目录结构如下(如果情况不同请自行调整理解):
本章节假定读者下载的是 本文的整合包 ,下载完成并解压到 D 后目录结构如下(如果情况不同请自行调整理解):
本章节假定读者下载的是 本文的整合包 ,下载完成并解压到 D 后目录结构如下(如果情况不同请自行调整理解):
voice_simulation
├─audio-slicer-gui-windows
├─audio-slicer-source-code
├─emoyun-ncm-convertor
│ ├─music
│ └─venv
│ └─converter.py
├─extracted-vocal-data
├─raw-data
├─sliced-data
│ └─rename_files.py
├─so-vits-svc
├─UltimateVocalRemover
├─so-vits训练
├─人声切片
└─提取人声
如果你下载的是 B站整合包 那么你看到的目录结构就应该只有
├─so-vits-svc
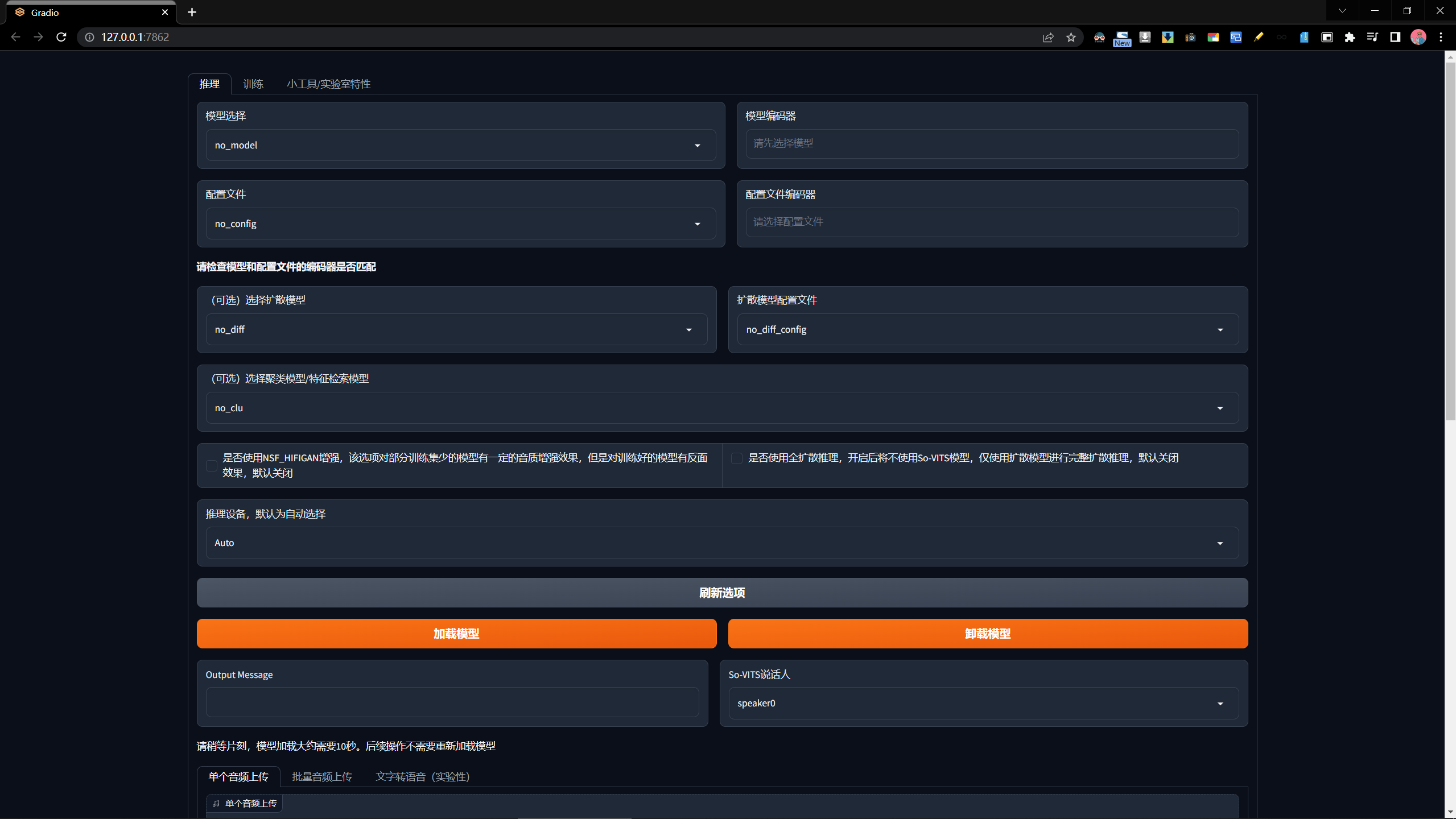
如果是文章整合包双击目录下的 so-vits 训练 自动将整合包的依赖添加到系统环境变量中;如果是 B站整合包,则进入目录后 双击 启动webui.bat。看到如下图所示的页面,则表示环境安装成功。
声音训练数据集准备
声音数据的采集和预处理
本文将训练歌手 肥振华 的声音模型为例。我们的训练数据为 12 首平均时长约 3 分 30 秒的歌曲。将这些数据下载下来,如果你是训练自己的声音,则将自己的露营数据传到电脑即可(实测采用手机录音即可,但要注意不要有太大的背景噪音即可,人生部分时长尽量在 20 分钟以上)。
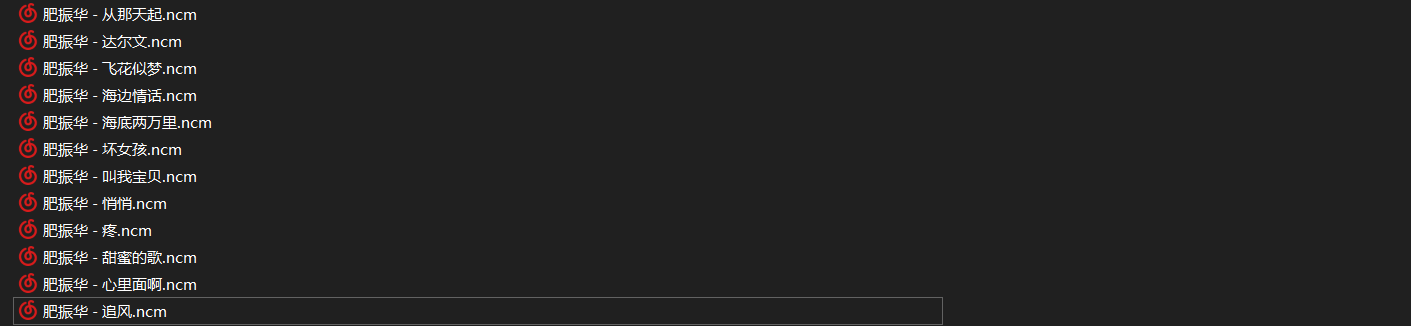
下载完足够的音乐数据后,将这些文件剪切至 emoyun-ncm-convertor/music 文件夹, 并然后进入 emoyun-ncm-convertor\venv\Scripts 文件夹, 在地址框中输入 cmd 并回车打开命令行工具。然后在命令行中输入:activate
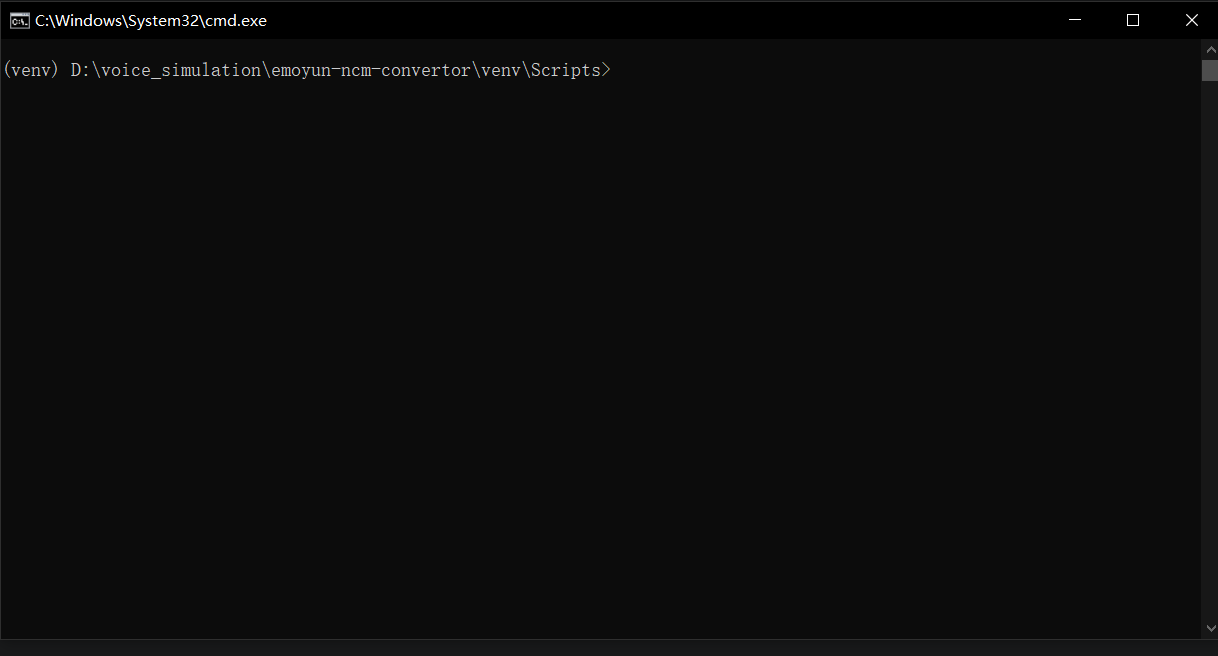
输入后,注意前面必须要有的 (venv);然后输入两次 cd .. 加 回车, 返回到emoyun-ncm-convertor 后 输入 python convertor.py 将 ncm 格式的素材转化为 MP3/wav。
声音数据的清洗
提取人声
本步骤旨在将声音素材中不是人生的部分去除掉,防止训练时产生不必要的干扰, 可以理解为提纯。
打开 voice_simulation 目录下的 提取人声。为了行成标准化的流程:
-
- 我们在 UVR5 中点击 Select Input, 打开你存放声音训练数据的文件夹(打开选择框时按住 ctrl 按件并点击你用于训练的声音文件);
- 点击 Select Output, 选择 voice_simulation\extracted-vocal-data ;
- 其他选项如下图所示;
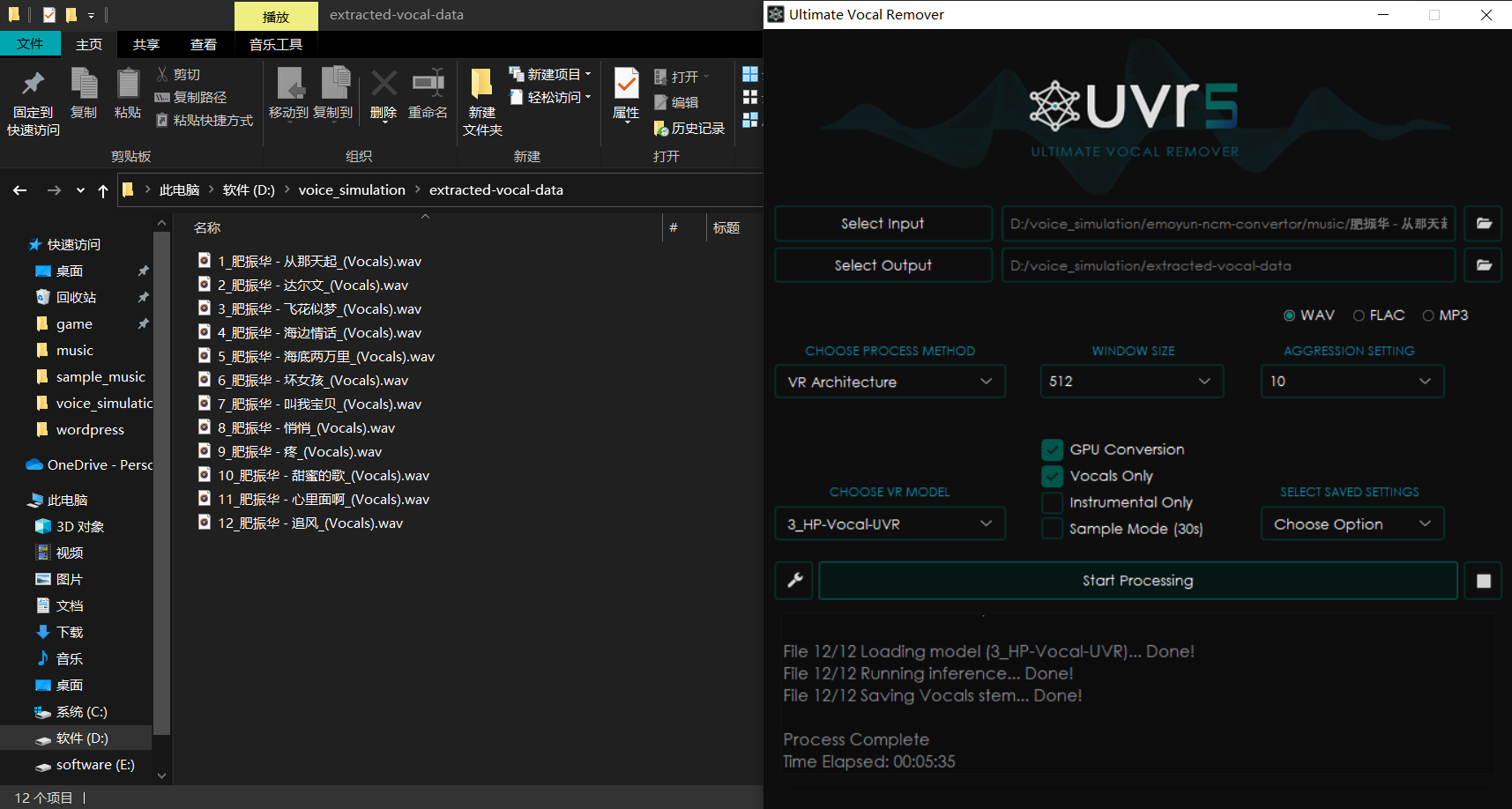
等待程序运行完成之后,可在 extracted-vocal-data 中看见仅剩下人声的声音素材。如果提取效果不满意,可尝试在 UVR5 界面中的 CHOOSE VR MODEL 选项框中选择不同的模型进行尝试;
人声切片
本步骤旨在将声音素材中无声的部分去除掉,防止训练时,没有人声的空白录音浪费CPU/显卡资源
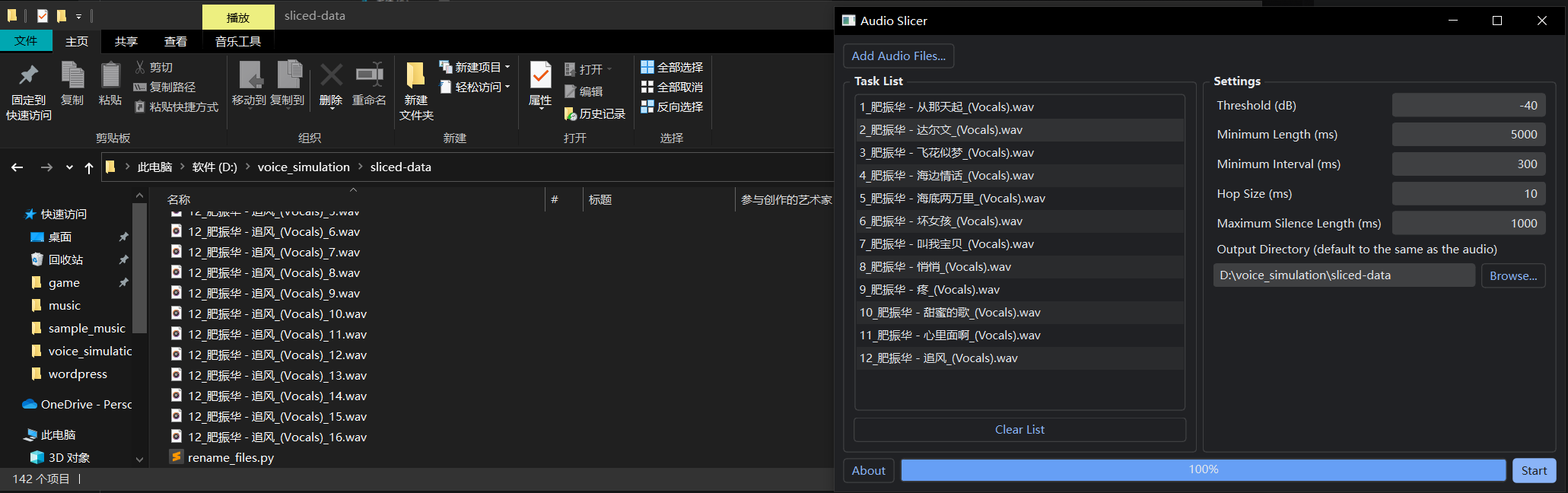
打开 voice_simulation 目录下的 人声切片。为了行成标准化的流程:
-
- 我们在 Audio Slicer 中点击 Add Audio Files, 打开 extracted-vocal-data ,将所有的人声文件选中;
- 点击右边的 Browse, 选择 voice_simulation\sliced-data ;
- 其他选项如下图右侧所示即可;如果发现 sliced-data 中的文件人声不纯粹,可以尝试调整 Settings 中的 Threshold 参数;
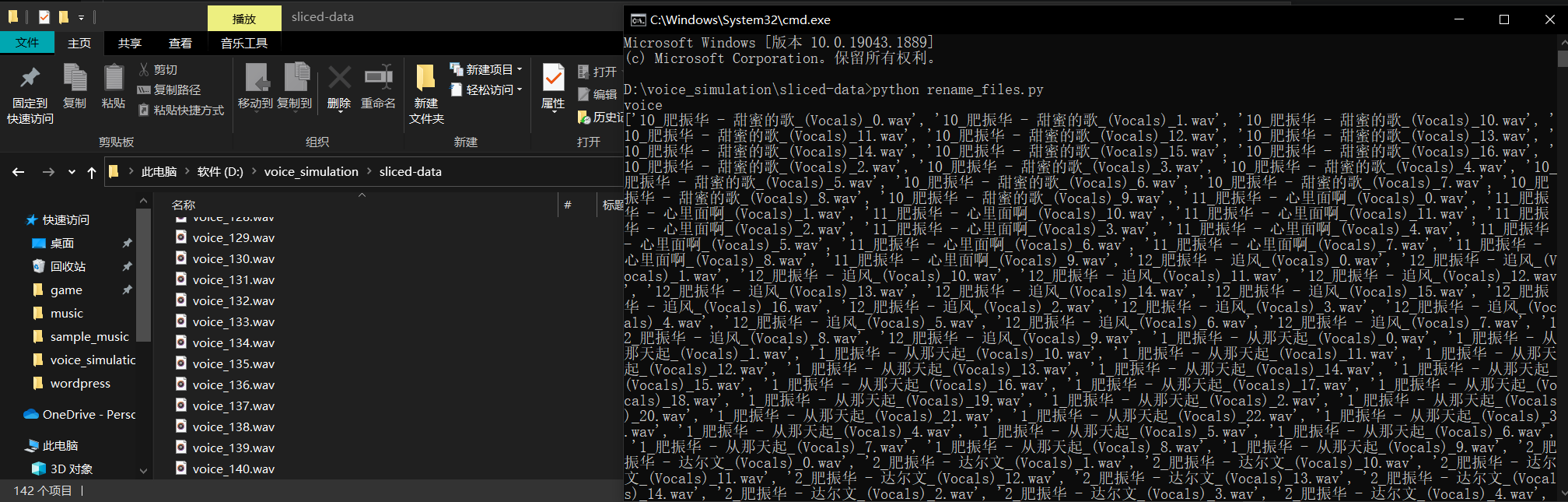
人声切片文件重命名,将声音文件标准化命名,防止特殊字符产生莫名其妙的 bug 。这个步骤直接运行预留在 sliced-data 文件夹下的 rename_files.py 文件即可:
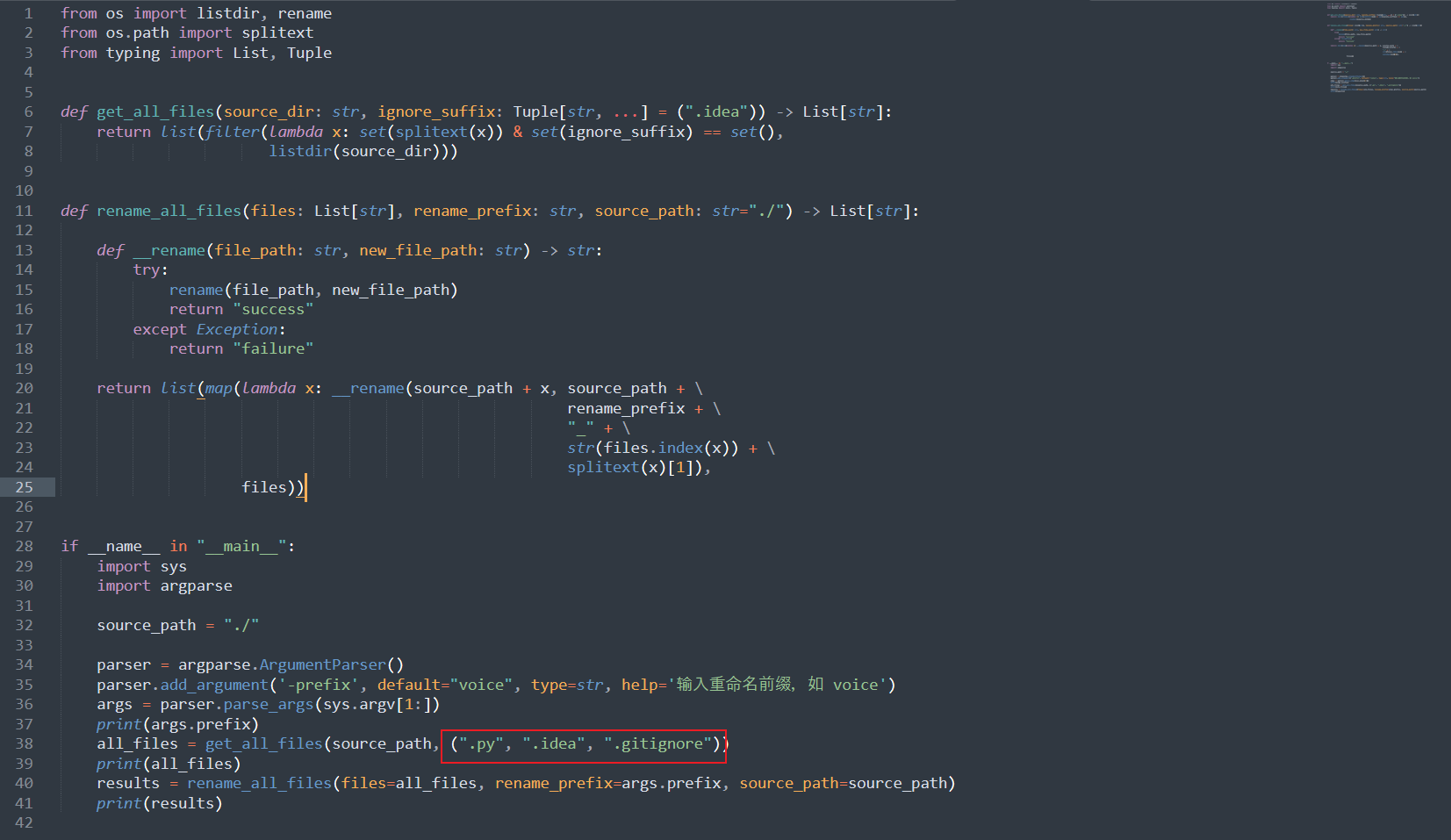
如果不喜欢 voice 这个固定前缀,可以在运行时增加参数 python rename_files.py -prefix FeiZhenHua ;这个文件还可以过滤非法后缀的文件,如需增加,可进入文件进行添加:
训练模型
首次训练
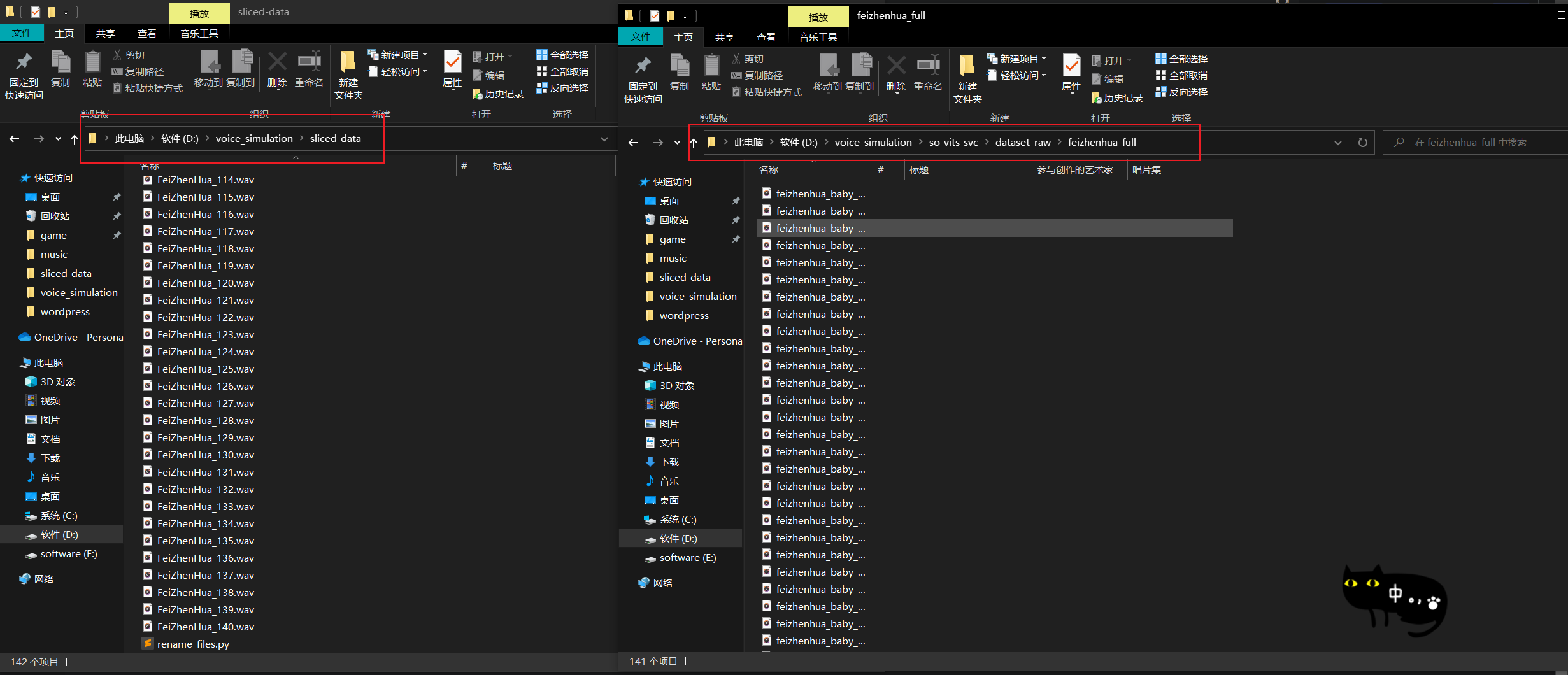
接上个步骤,我们在 voice_simulation\so-vits-svc\dataset_raw\ 下建立 一个文件夹,名字最好起一个正经一点的,这个名字会在后续模型训练好进行使用时显示。
然后,将 sliced-data 文件夹下的所有 音频文件 拷到这个文件夹下(我这里是feizhenhua_full),注意不要将 rename_files.py 也拷过去了,否则在后续的数据预处理环节会报错。
接下来,我们返回到 so-vits-svc 文件夹 执行 python setup.py 以及 python setup.py, 如果不能正常执行,则改为执行 .\workenv\python setup.py 以及 .\workenv\python setup.py , 或者直接双击 启动webui.bat 均可。在执行后,浏览器会打开一个页面,然后我们切换到 训练 选项卡
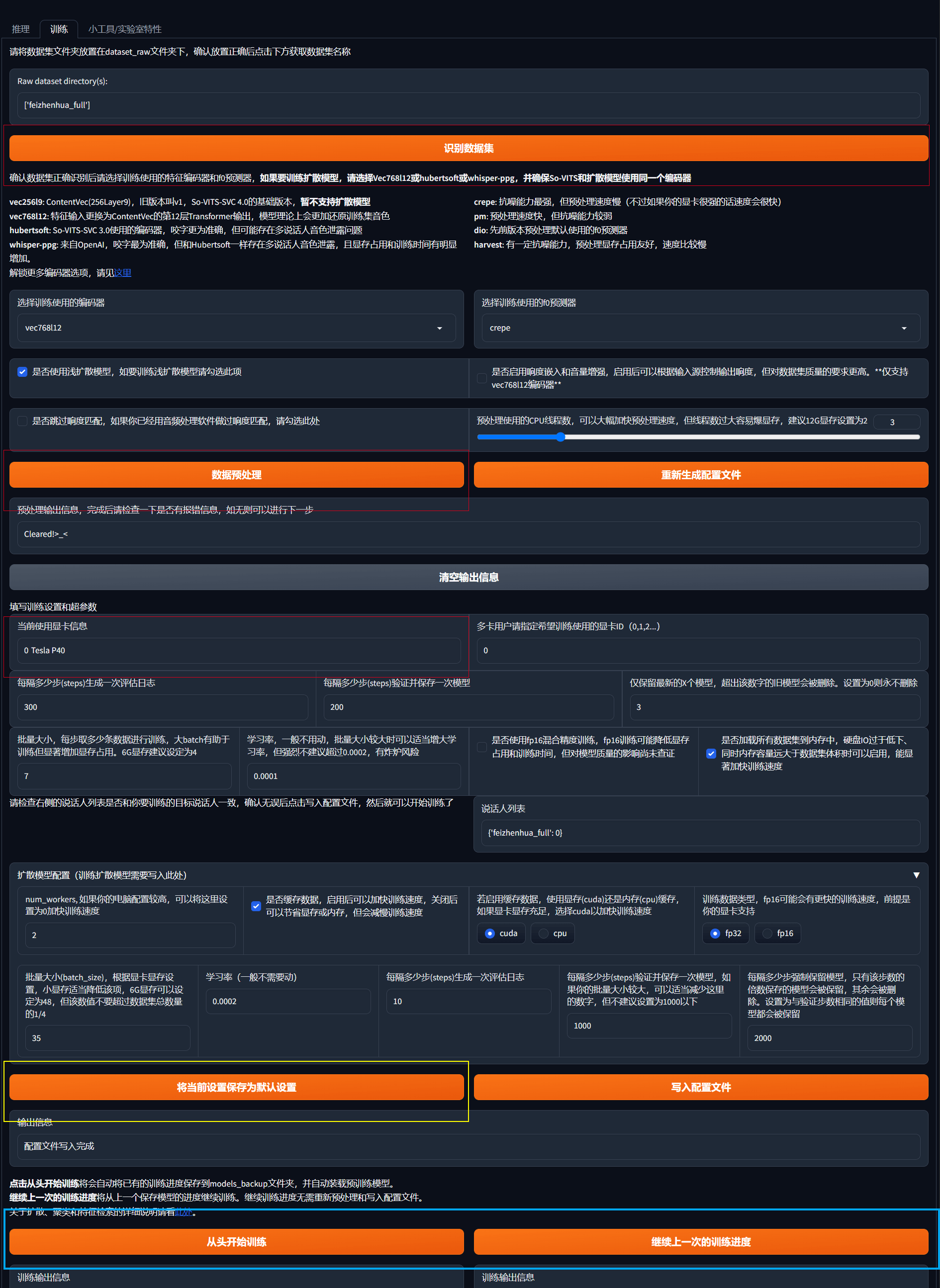
然后可以参考下述的操作步骤:
-
- 点击 识别数据集 ;如果你严格按照上面的步骤执行下来,那么点击这个按钮之后,我们按钮上方会显示出你的数据集所在的文件夹名称(就是你起的那个名字);
- 然后点击 数据预处理; 等预处理输出信息不再变化时,即表示预处理完毕,如果上面在拷数据的时候,将 .py 文件也拷过来,那么在此阶段就会报错;
- 选择进行训练的显卡,这里务必要选择独立显卡,如果选择了核显会非常慢;
- 点击 将当前设置保存为默认设置;点击之后,程序会修改 voice_simulation\so-vits-svc\configs\ 路径下的 config.json 和 diffusion.yaml 两个文件;这样修改后后续就不必每次都修改了;但需要注意的是,这样操作之后默认的训练轮数是10000,如果你认为不需要这么多的轮数,可在此时修改 voice_simulation\so-vits-svc\configs\config.json 这个文件中第六行的 epochs 参数 ,如 5000;但建议不要修改到低于1000;
- 其他参数根据自己的情况酌情调整;
- 最后点击 从头开始训练 ;
之后程序会开始训练并显示训练进度:
此时,等待训练完成获得最终模型 或 在达到某个检查点 时获取验证效果的模型 即可。这里的耗时根据你数据量的不同,batchsize | num_worker 参数的不同 以及 你显卡/cpu的性能差异都有关系,耐心等待即可。
中断后继续训练
基本步骤和首次相同:
-
- 点击 识别数据集 ;如果你严格按照上面的步骤执行下来,那么点击这个按钮之后,我们按钮上方会显示出你的数据集所在的文件夹名称(就是你起的那个名字);
- 然后点击 数据预处理; 等预处理输出信息不再变化时,即表示预处理完毕,如果上面在拷数据的时候,将 .py 文件也拷过来,那么在此阶段就会报错;
- 选择进行训练的显卡,这里务必要选择独立显卡,如果选择了核显会非常慢;
- 最后点击 继续上一次的训练进度 ;
获取最终模型 | 中间模型
在训练完成 或 训练轮数 超过检查点(或检查点的整数倍的轮数) 时, 你可以在 voice_simulation\so-vits-svc\models_backup 或者 voice_simulation\so-vits-svc\logs\44k 找到对应的模型文件
这里我们选择从 voice_simulation\so-vits-svc\logs\44k 中获取 G_数字最大 的 .pth 文件 以及 对应的 config.json 文件,即:
-
- voice_simulation\so-vits-svc\logs\44k\config.json
- voice_simulation\so-vits-svc\logs\44k\G_XXXX.pth
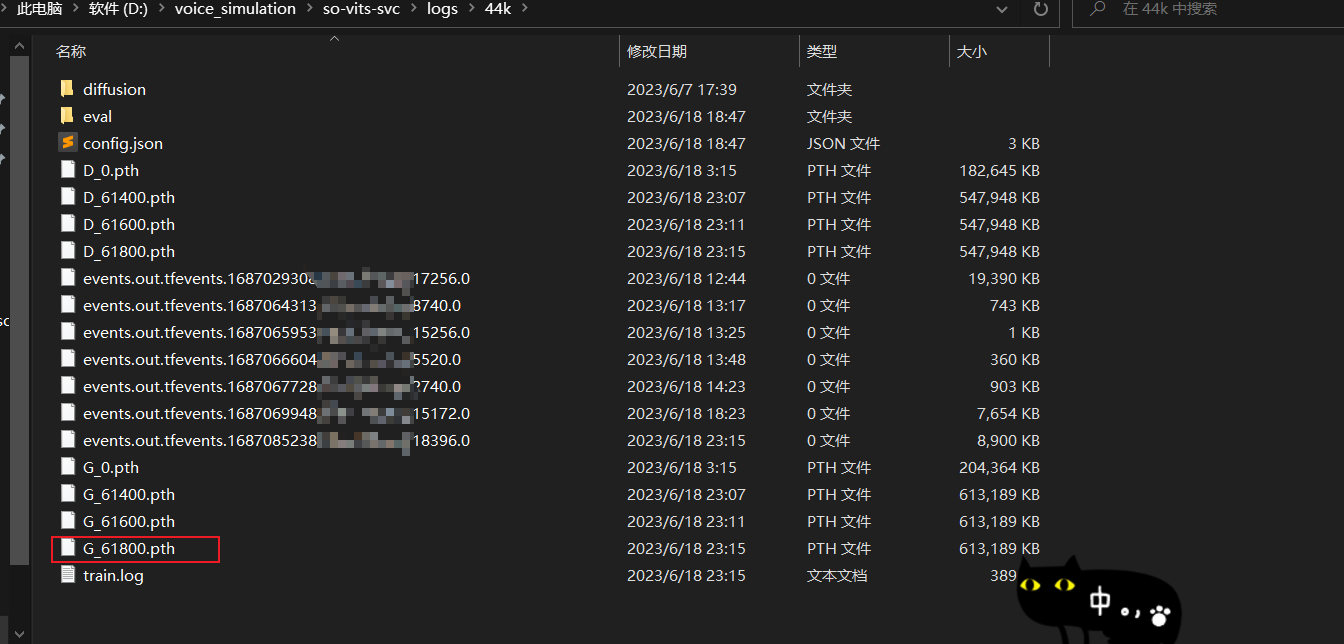
这两个文件就是我们训练出来的模型,在进行声音替换时需要用到。注意 config.json 也很重要!
建议将训练完成的模型以及配置文件保存到合适的地方,方便后续进行推理时查找和使用(效果不错的中间模型同理);这里我将可用的模型放到了 voice_simulation\so-vits-svc\TRAINED_MODELS\feizhenhua_full:
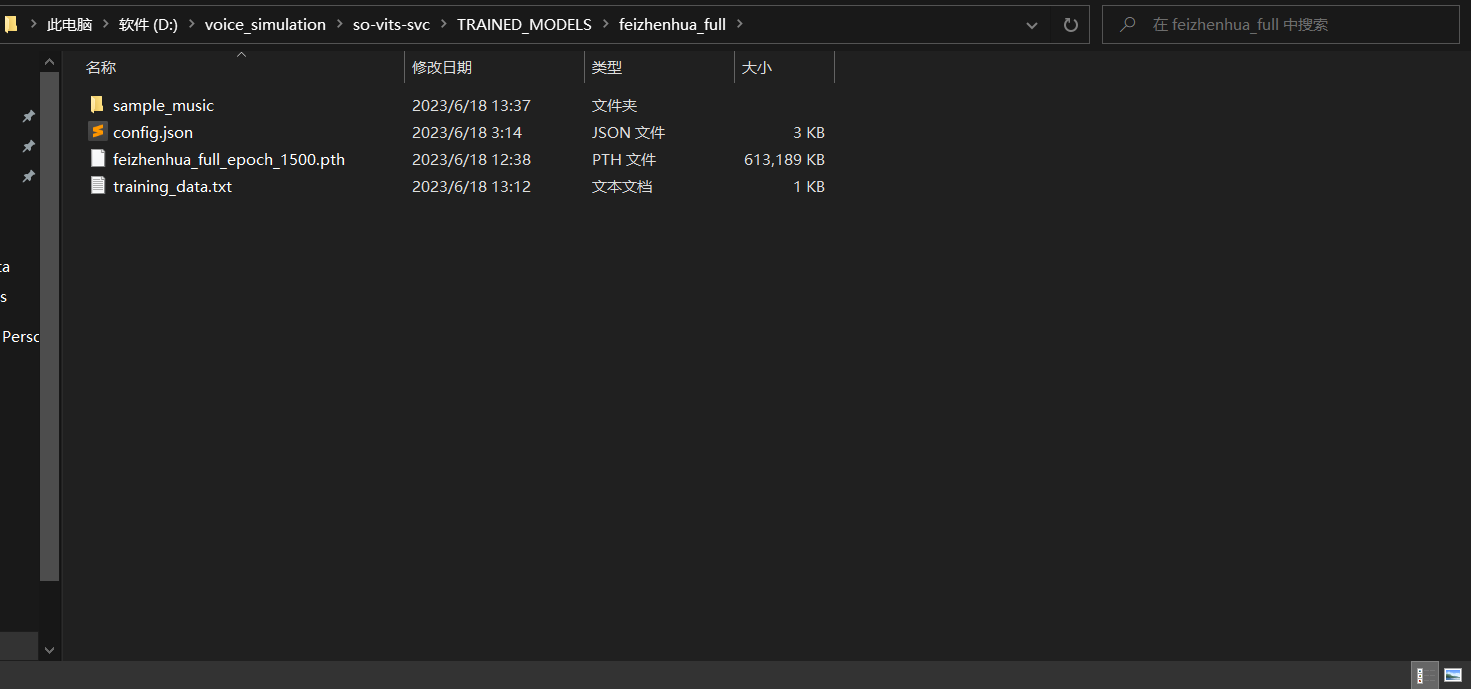
模型使用
推理页面及参数配置
可以尝试图中顶部的 推理 选项卡,但这个选显卡中的功能在我电脑上无法生效。因此,建议使用另一种方法进行 推理 。
在 voice_simulation\so-vits-svc\ 目录下运行命令 .\workenv\python.exe webUI.py
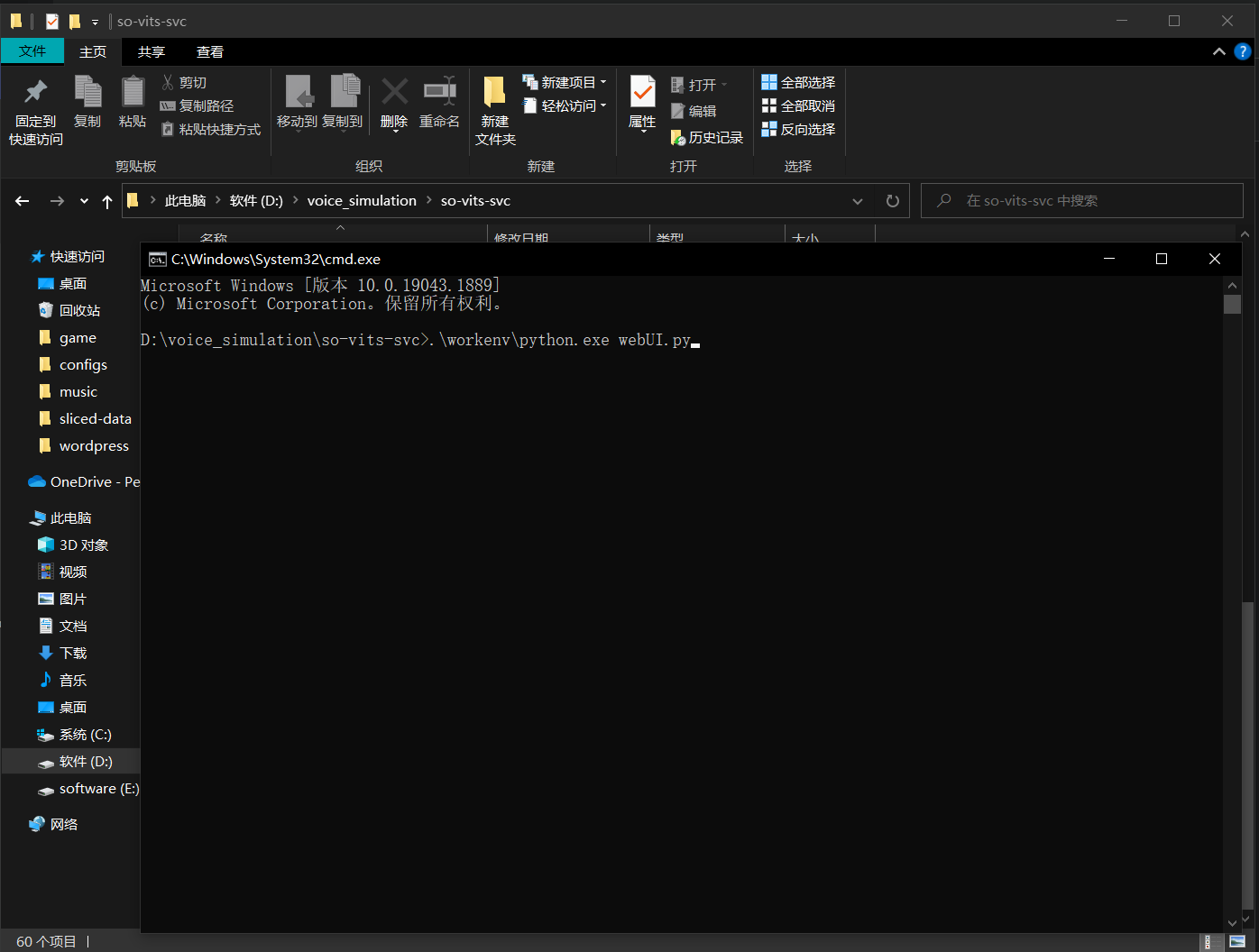
运行后按照参考下图,进行配置:
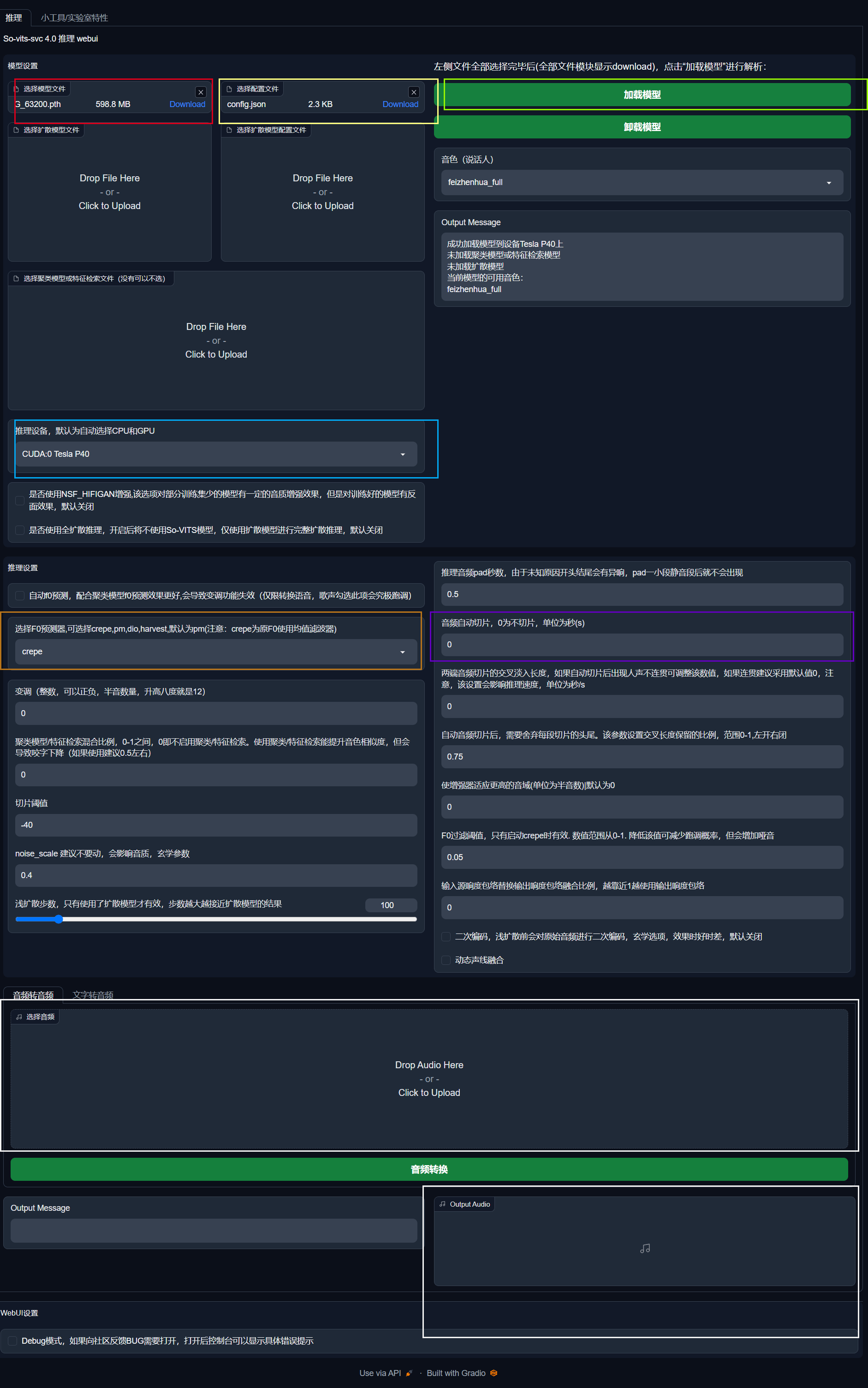
-
- 将模型和对应的配置文件加载到对应的位置,然后点击加载模型,当讲话人被读取出来则表明加载成功,否则就好检查对应的 config.json 是否与 pth 模型匹配及完整;
- 将推理设备设置为您的独立显卡(虽说用 cpu 也可以);
- 如果后续推理时,报错爆显存,则调整紫色框的参数,比如调整成20秒切片一次即可;
- 择 F0 预测器,这个如果发现产出的文件会破音,建议更改为 crepe;
准备需要替换的歌曲或录音文件
这里我们以用 肥振华 的声音 替换 陈粒 来唱歌曲 小半 为例
这里方法很简单,和清晰数据是的操作类似,只需要注意图同黄色框部分不要勾选 Vocals Only 和 Instruments Only 即可;
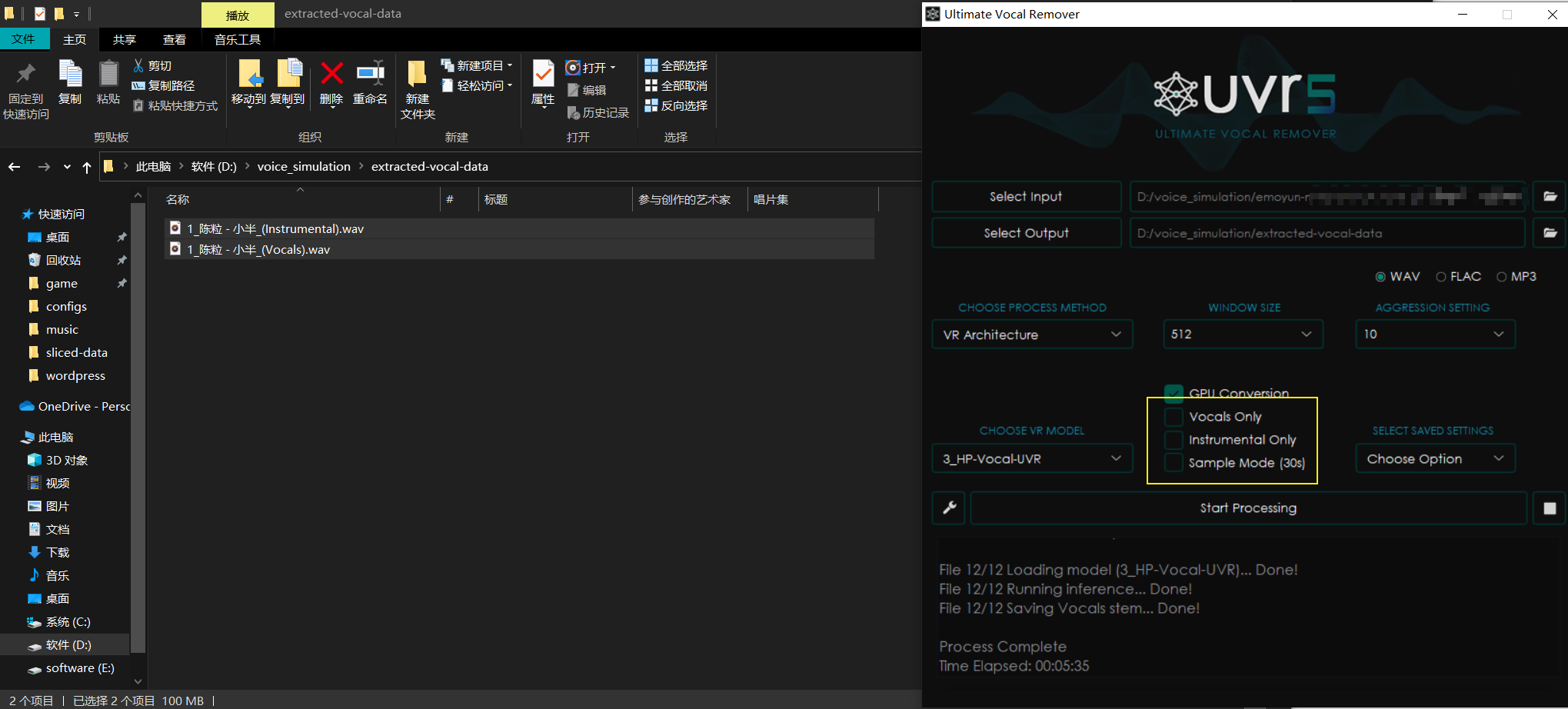
然后我们将 1_陈粒 - 小半_(Vocals).wav ,加载到页面 然后 点击 音频转换 :

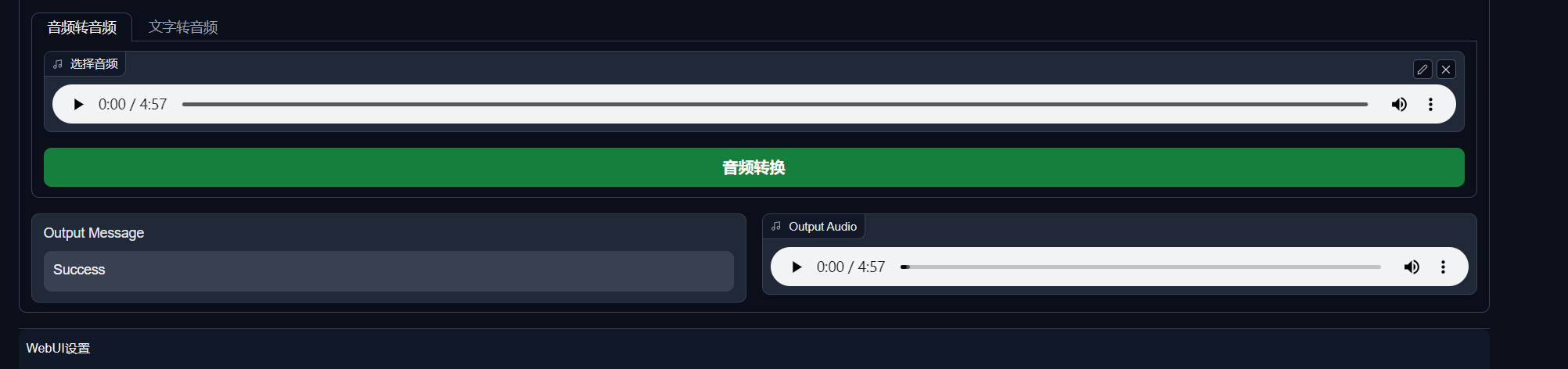
训练完成后,我们点击 Output Audio 栏的 “三点”按钮,将替换后的音频下载,最后将只有伴奏的 1_陈粒 - 小半_(Instrumental).wav 和 下载下来的 Output Audio 用剪辑软件 合成即可:
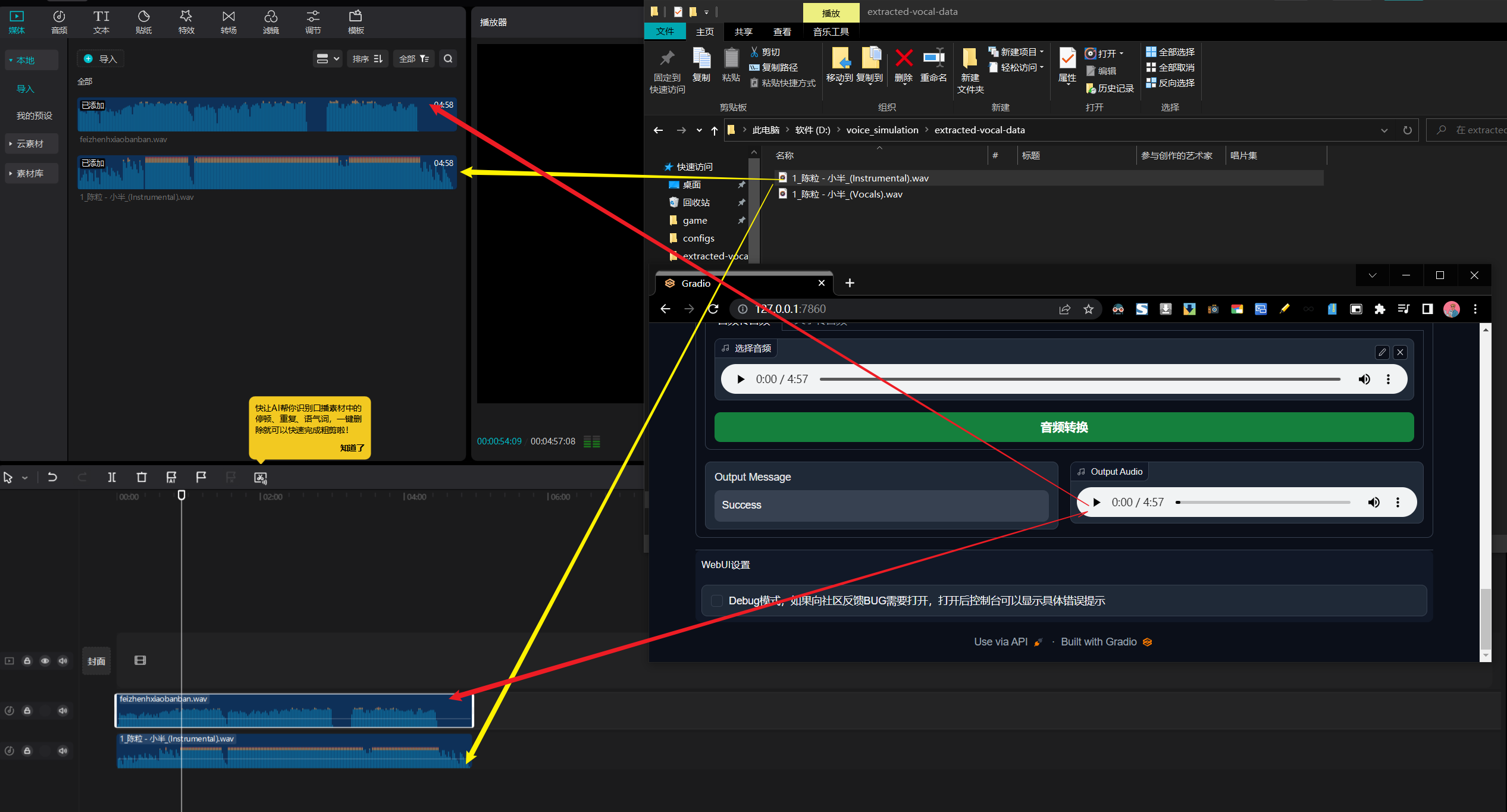
文件的关系如上图所示,enjoy~
注意事项
请参考:https://www.yuque.com/umoubuton/ueupp5/dkuhbeyl4g9qolo9
下载内容
feizhenhua_full_epoch_3200
链接:https://pan.baidu.com/s/14IR3O_pwnE4SZ9qz2NxjkQ?pwd=7e95
提取码:7e95
B站新版整合包
链接: https://pan.baidu.com/s/1x0iUxrmd5_Td4HZqbYQ8Gg?pwd=smbm
提取码: smbm
本文项目包
链接:https://pan.baidu.com/s/1cg7SCvyWQrhOLhZheeWYcg?pwd=5vu8
提取码:5vu8
Comments NOTHING