

第一天:一切就绪
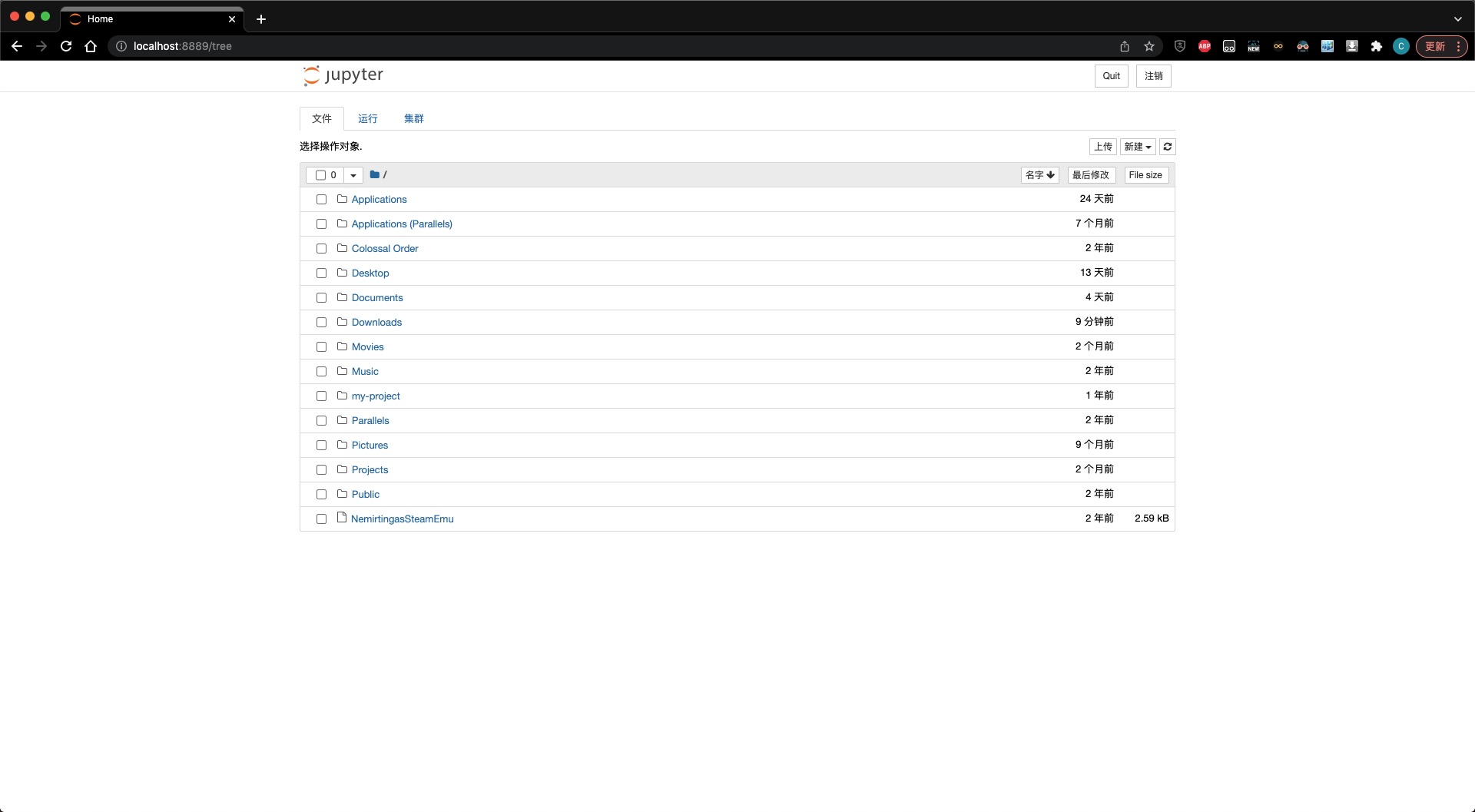
数据预处理的基本步骤
根据 day_1 的原文,我们可以总结出数据预处理的基本流程:
- 导入数据处理相关库:其中最常见的库是 numpy 以及 pandas 。其他的库可以根据需要再进行导入;
- 导入数据集:数据集一般是.csv或.xlsx格式的文件(如果不是这类型的比如sql等,则可事先转为正确的格式)。这种文件最大的每一行都是一条数据记录。导入数据集我们一般使用pandas的read_csv()方法,读取后,将其转为一个数据帧。之后我们可以再根据具体的业务选取自变量矩阵及因变量向量;
- 处理丢失数据:如遇到数据集不完整的情况,为不影响模型的性能,或纯粹为了模型能够跑起来,我们需要处理数据中的空值(或其他类型的非数值),并用整列的均值、中值、众数或特定的常数进行处理。完成这一步骤我们可以使用 sklearn.impute 中导入SimpleImputer 方法来进行处理;
- 解析分类数据(Encoding categorical data):分类数据指的是还有标签值而不是数字的变量(如定序、定类以及定距变量等,或其他的非数字标签)。这类型的数据通常是固定的,如原始数据中的 purchased 向量中的 YES 和 NO。但这些标签是无法进行数学计算的,因此我们要根据一定的规则,将其转换为数字。通常,我们可以通过 sklearn.preprocessing 库中的 LabelEncoder 类 来完成这一步骤的处理;
- 将数据集拆分为训练集和测试集:其中训练集用于训练模型。训练好后,再用测试集来验证模型预测的结果。一般来说,这两者的数据量比为 ----> 训练集:测试集 = 80:20 。而拆分数据集可以我们可以通过 sklearn.crossvalidation 中的tran_test_split()方法实现。
- 特征缩放(Feature Scaling):大部分模型算法在计算两点间的距离时一般用欧式距离。但此特特征在幅度、单位以及范围上变化很大。在距离计算时,高幅度的特征比低幅度的特征权重更大。为此,可使用特征标准或Z值归一化将所有数据映射到[0,1] 或 [-1, 1]区间内,避免"距离"数量级差距过大的影响。(参考:这里)
创建项目目录
进入 Jupiter Notebook 后,我们需要做的第一件事就是在自己喜欢的位置新建一个文件夹,作为我们项目的工作目录。后续中,我们的代码、数据集都将放置在这个目录中。一个整洁、清晰的项目项目文件结构,可以在很大程度上提高我们的效率并且减少犯错的几率。
在这次项目中,项目的文件结构如下图所示:

当然,也可以有其他的文件归纳方式。之所以这么归纳的原因在于,如第0天中所说,100-Days-Of-ML-Code 这个项目每天的内容差异巨大,且所用到数据集也大相径庭。更重要的是,我希望可以达到,打开某天的笔记,即可将相关内容尽收眼底,没有遗漏。当然,也不需要在自己想要查看数据的原始文件时,在无数的文件夹中切换查看。
这样的思维方式在项目中的具体体现可以是这样的:
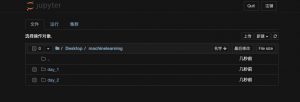
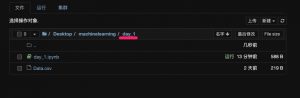
我们进入到 day_1 文件夹,进入 day_1.ipynb 文件,即可开始编写day_1的相关代码。
查看原始数据

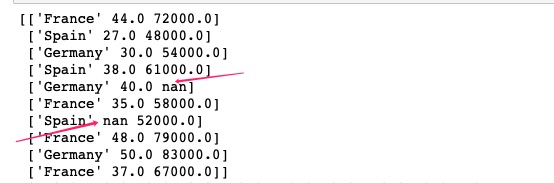
可以看到,这是一组比较简单的数据。这组数组中包含 country(国籍)、age(年龄)、salary(收入)、 purchased(是否购买)几个维度。
需要注意的是,其中的Age 以及 Salary 这两列中存在空值。但不用担心,这点我们在数据预处理/数据清洗阶段会解决这个问题。
此外,在这里,我们可以猜测:
似乎尝试通过国籍、年龄、以及收入等几个自变量变量去预测购买结果的因变量
开始编码
导入库和数据集
import numpy as np
import pandas as pd
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[ : , :-1].values
Y = dataset.iloc[ : , 3].values
处理丢失数据
from sklearn.impute import SimpleImputer as Imputer
imputer = Imputer(missing_values = np.NAN, strategy = "mean")
imputer = imputer.fit(X[ : , 1:3])
X[ : , 1:3] = imputer.transform(X[ : , 1:3])
注意,此处不能按照github上的源代码进行处理,因为新版的sklearn已经没有imputer函数。需按照本文中的方法进行处理。
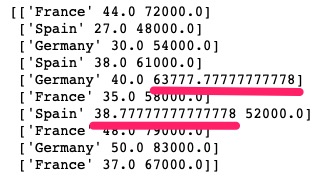
使用 SimpleImuter 方法处理空值时,我们注意stategy参数,此处我们选择“mean”即均值,意思为将该列所有的空值替换为该列所有非空值的均值。参数其他可选的值为:
The imputation strategy.
If “mean”, then replace missing values using the mean along the axis. 使用平均值代替If “median”, then replace missing values using the median along the axis.使用中值代替
If “most_frequent”, then replace missing using the most frequent value along the axis.使用众数代替,也就是出现次数最多的数
我们可以验证一下age列:
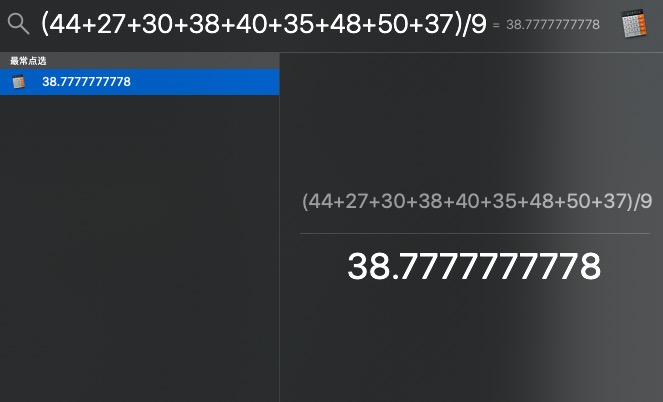
手动计算值与 SimpleImputer 给出的结果一致(注意该列非空值有9个所以除数为9)。
另外,Imputer和SimpleImputer这两个方法的区别为:
SI = SimpleImputer(missing_values=np.NAN, strategy=’mean’)
I = Imputer(missing_values=’NaN’, strategy=’mean’, axis=0, verbose=0, copy=True)
其中最大的区别为 SimpleImputer没有axis参数,默认为按列处理。这也要求我们在搜集处理数据集时,需要严格按照标准。
解析分类数据
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0])
print(X[ : , 0])
运行结果为:[0 2 1 2 1 0 2 0 1 0]
这段代码做了什么呢?我们看一下下图。这段代码将数据集中的 country 一列数据由文字转为了数字。有意思的是,X[ : , 0]具有与innerHTML类似的功能:既能取值,也可赋值。
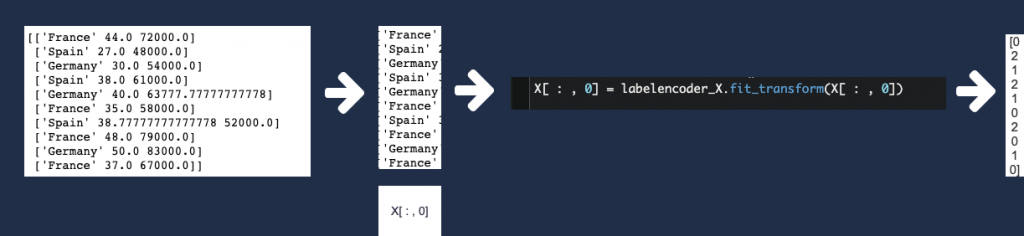
创建哑变量
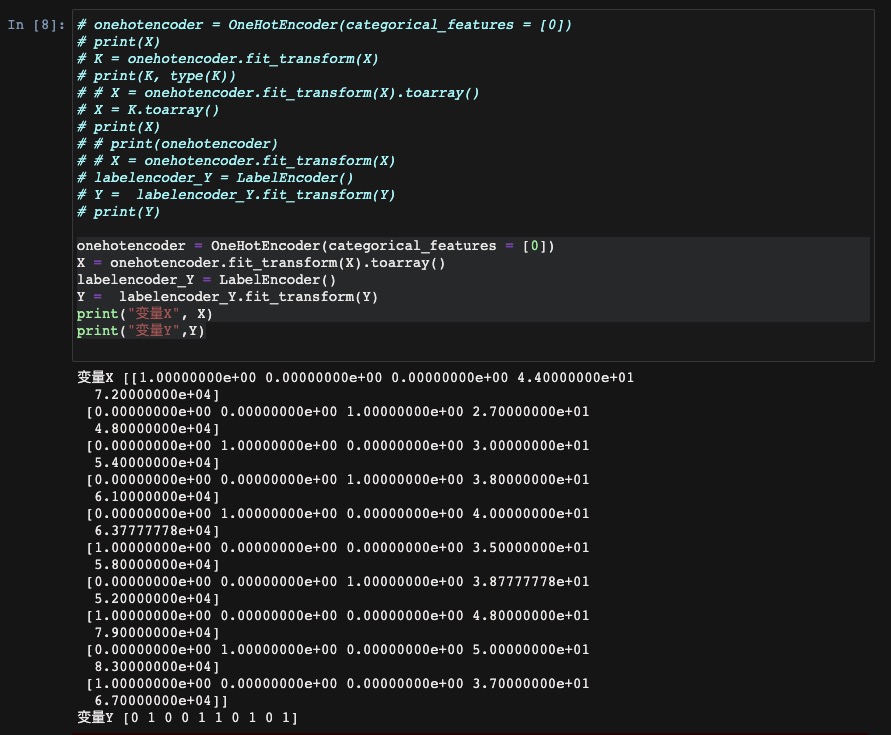
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
print("变量X", X)
print("变量Y",Y)
拆分数据集为训练集合和测试集合
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0)
注意,原文中的from sklearn.cross_validation import train_test_split 已失效,需替换为上文代码中的语句。
特征缩放

from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.fit_transform(X_test)
print(X_train, X_test)
相关知识补充
至于fit_transform()相关的
笔记下载
Data, day_1.ipynb" rel="external" target="_blank" title="下载地址"> Download
Comments NOTHING